Ⅰ. 서 론
Ⅱ. 중장기 지역별 전력 판매량 예측 모형
1. 지역별 판매량 데이터 특성
2. 판매전력량 패널모형
3. Bootstrapping을 통한 편의 보정
4. 지역별 산업구조 변화
5. 소득계수 평면 확장 및 지역별 판매량 예측
6. 머신러닝 기법을 이용한 지역별 판매전력량 예측
Ⅲ. 지역별 비동시 최대전력 모형
1. 지역 부하 데이터 현황
2. 지역 부하 이상치/결측치 선형 보간 및 추세 보정
3. 비동시 최대전력 예측모형
4. 비동시 최대전력 예측결과
Ⅳ. 결 론
◎ 부 록 ◎
Ⅰ. 서 론
최근 재생에너지 보급확대 및 탄소 중립 정책에 따른 장기적인 국가 전력 수립은 새로운 전기를 마련하고 있다. 특히 송변전 시설 제약에 따른 문제가 일부 지역에서 발생하고 있으며 이는 발전소의 출력제한으로도 연결되고 있다. 실제로 에너지경제연구원에서는 동해안 지역의 대규모 발전설비 확대에 따른 수도권・동해안 송전제약 문제와 호남지역의 태양광 설비 급증에 따른 수도권・호남지역의 송전설비 문제를 발전 부문의 주요 이슈 중 하나로 제시하였다(에너지경제연구원, 2023). 또한, 제10차 전력수급기본계획에 재생에너지 발전 비중 확대와 일부 지역 보급 집중이 수급 불균형과 주파수 안정도 저하 등의 계통 불안정을 증가시키는 것으로 나타나 있다(산업통상자원부, 2023). 이러한 송변전 시설 제약과 재생에너지보급 확대로 인해 선제적 전력망 보강의 중요성이 증가하고 있으며, 정부에서 수립하는 전력수급기본계획의 패러다임도 발・송전 통합계획으로 전환되고 있다(산업통상자원부, 2021).
지역간 전력 수급 불균형에 따라 지역별로 다른 요금체계를 도입하는 지역별 차등 전기요금제 도입이 활발하게 논의되고 있다. 수도권의 전력 수급 불균형 현황을 보면, 전국 대비 수도권의 발전량 비중은 약 24.3%이지만 판매전력량의 비중은 약 39.2%로 발전량은 적지만 사용량은 많은 양상을 보인다. 이러한 지역간 전력 수급 불균형에 따라 이정섭・이강원(2023)에서 연구된 것처럼 지역별 차등 요금제 및 자급률에 관한 논의도 활발히 진행되고 있다. 이러한 논의를 위해서는 지역별 전력소비량과 최대전력수요를 예측하고 분석하는 것이 필요하다. 특히, 정책적으로 변압기 증설과 변전소 신설 등을 검토하기 위해서는 중・장기 예측이 필수적이다. 또한, 중・장기 예측은 지역별로 불균형하게 발전되고 있는 재생에너지를 적기에 전력계통에 연계하여 전력계통 운영의 신뢰성을 확보하는 것의 기반이 된다.
이처럼 지역별 수요분석과 예측에 관한 관심은 필연적으로 증가하고 있으나, 일부 연구를 제외하고는 의미있는 분석연구 결과가 도출되지 못했다고 판단된다. 안병훈 외(2015)에서는 계절 ARIMA모형으로 향후 12개월의 월별 지역별 전력 소비량을 예측하였고, 이후로 임혜원 외(2021)에서 딥러닝 모형을 이용한 연구가 있었으나 이를 적극 활용하기에는 제한적인 측면이 존재한다. 지역별 수요 분석에 대한 체계적인 연구가 국내에는 거의 없었던 이유 중 하나는 가용할 수 있는 데이터가 한정적인 것에서 기인한다. 특히, 지역별 소비량 데이터로 활용할 수 있는 지역 부하 자료가 구축되지 않아 활용할 수 없었으며, 최근에 구축된 지역 부하 자료 또한 재정비가 필요하여 의미 있는 결과를 도출하기 어려운 실정이다. 해외의 사례에서도 의미 있는 지역별 수요예측 연구는 제한적이다. Hsu and Chen(2003)은 ANN(Artificial Neural Network)을 이용한 대만의 지역별 최대전력수요 예측과 그에 따르는 대만 전력시장 개선 필요성에 대해 논의했으며, Hong et al.(2015)에서는 지역별 부하 예측을 위한 기온관측 장소의 선정에 대한 기본 프레임을 제시했다.
본 논문에서는 17개 광역 시도별 전력소비량을 추정하고 예측하며, 이러한 예측치를 기반으로 9개로 구분된 지역의 최대전력을 추정하고 예측한다. 먼저, 지역별 전력소비량 자료 중 가장 신뢰성이 있는 한국전력의 판매전력량 데이터를 활용하여 17개 광역 시도의 중・장기 연별 판매전력량을 분석하고 예측모형을 구성하였다. 이를 위해 Chang et al.(2016)에서 제시되었고 최용옥・양현진(2019)과 Chang et al. (2021, 2024) 등에서 응용된 불균형 패널모형(Unbalanced Panel)을 이용하였다.
Galli(1998), Judson et al.(1999), Liddle and Huntington(2020)과 Liddle(2022) 등에서는 소득수준과 에너지소비 간의 비선형 관계에 대한 실증분석 결과를 제시하고 비선형성에 대한 추정 방법을 제시하였다. 이러한 선행연구와는 다르게 본 연구에서는 불균형 패널모형의 비모수(nonparametric) 추정 방법을 이용하여 지역별 소득과 에너지소비 간의 비선형성에 관한 공통요인과 개별요인을 각각 식별하고 그에 대한 해석을 가능하게 하였다. 또한, FPCA(Functional Principal Component Analysis)방법을 활용하여 기존 연구에서 거의 다루어지지 않았던 표본 외 데이터(out-of- sample)의 지역별 에너지 수요예측을 가능하게 하였다. 이외에도 지역별 산업구조의 차이를 반영할 수 있는 지역별 전력수요 산업지수를 구성하고, Su et al.(2016)에서 제시한 C-Lasso 방법론을 사용하여 산업구조 차이에 의한 판매전력량의 변화가 유의미함을 확인하였다.
불균형 패널모형 예측치의 강건성 확인을 위해 머신러닝 기법의 일종인 Gradient Boosting 방법으로 지역별 1인당 판매전력량 증가율을 예측하였다. 지역의 판매전력량에 영향을 줄 수 있는 25개의 특성(features)을 이용하여 지역별 판매전력량 예측실험을 한 결과, 향후 2년의 예측에서 불균형 패널모형에 준하는 예측성과를 나타냈다.
또한, 본 논문에서는 불균형 패널모형의 전력소비량 예측치를 바탕으로 지역별・월별 최대전력 모형을 제안하고 그 예측력을 평가한다. 지역별 최대전력 분석을 위해서는 지역별・시간별 데이터가 필수적이며, 이를 구축하기 위해 우리는 주변압기와 직거래 데이터를 통해 추산한 지역별・시간별 자료를 활용하였다. 하지만 대부분의 지역 부하 원시자료를 대응하는 판매전력량에 배전 손실량을 더한 자료와 비교했을 때 지역 부하 자료가 전체적으로 과소하다는 사실을 확인했다. 따라서 본 논문에서는 지역 부하 자료를 보정하고 해당 데이터를 검증하는 작업을 거쳐 최종적인 지역 부하 데이터베이스를 구축하였다.
이렇게 보정된 지역 부하를 기반으로 지역별 비동시 최대전력 예측 모형을 구성하였다. 최대전력 모형에서는 지역별 최대전력을 추세와 기온효과로 분해하였고, 최대전력과 판매전력량이 강한 상관관계를 보이는 것을 활용하여 판매전력량과 시간에 따라 달라지는 최대전력의 추세를 추정하였다. 또한, 동일한 기온에서도 최대전력이 달라지는 것을 모형화하기 위해 비모수 추정 방법을 사용하여 시간에 따라 달라지는 기온반응도를 추정하고 예측했다.
본 논문의 구성은 다음과 같다. Ⅱ장은 비교적 안정적인 데이터가 구축되어 있는 지역별 판매량의 특성과 중장기 지역별 판매량 모형을 소개한다. Ⅲ장에서는 지역별 시간별 부하 데이터 구축 및 보정에 대하여 논의했다. 이를 바탕으로 지역별・월별 최대전력 예측모형을 제안하고, 실증분석과 예측실험 결과를 제시했다. 마지막으로 Ⅳ장에서는 요약 및 결론을 제시한다.
Ⅱ. 중장기 지역별 전력 판매량 예측 모형
1. 지역별 판매량 데이터 특성
본 논문은 지역별 장기 전력소비량 예측을 위해 한국전력공사(이하 한전)의 한국전력통계에서 제공하는 17개 광역 시도의 판매전력량 자료를 사용했다(한국전력공사, 2023). 판매전력량은 정산 이후 확정되는 데이터로, 극히 일부 자료를 제외하고는 정확도가 매우 높다.1)
지역별 판매량 데이터는 전반적으로 증가하는 공통적인 특성을 보이나, 1인당 판매전력량의 크기와 증감 폭은 지역별로 차이를 보인다. 예를 들면, 중화학공업이나 반도체 등 산업이 발달한 도시에서는 1인당 판매전력량이 전국의 평균보다 높다. 특히, 중화학공업이 밀집해 있는 울산광역시의 2023년 1인당 판매전력량은 28,768 kW로, 전국의 1인당 판매전력량보다 약 2.7배 높다. 이외에 제조업 단지가 집중된 충청남도, 충청북도, 전라북도, 전라남도와 경상북도의 1인당 판매전력량이 전국의 판매전력량보다 높다. <표 1>에 따르면 이들 지역 중 전라북도를 제외하면 1인당 GRDP 또한 전국의 평균보다 높은 특성을 보인다.
1인당 GRDP가 높은 지역 중 서울특별시의 1인당 판매전력량은 전국의 17개 광역 시도 중 가장 낮은 수치를 기록하였는데, 서울특별시는 제조업의 비중이 작고 부가가치당 전력을 적게 사용하는 서비스업 등이 발달하였기 때문이다. 2020년 기준 서울특별시의 제조업 비중은 4% 미만인 반면, 부가가치당 판매전력량의 비중이 낮은 도매 및 소매업, 정보통신업, 금융 및 보험업과 사업서비스업의 부가가치 합의 비중이 약 60% 이상이다.
1인당 판매전력량과 GRDP의 관계가 지역별로 다르다는 것은 판매전력량의 소득탄력성이 지역별로 다르다는 것을 의미한다. 본 연구에서 이러한 특성을 반영하기 위해 판매전력량이 소득에 따라 공통적으로 변화하는 소득계수와 지역에 따라 다르게 변화하는 소득계수를 식별하여 추정하였다. 또한, 판매전력량과 소득의 관계가 시간에 따라 달라지는 것을 함께 모형화하기 위해 다음 절에 소개되는 불균형 패널모형을 도입하였다.
<표 1>
2023년 1인당 판매전력량과 GRDP2)
2. 판매전력량 패널모형
에너지 수요의 정형화된 사실 중 하나는 에너지 소비와 국내총생산(GDP)의 비율로 나타낸 에너지 집약도(energy intensity)가 시간에 따라 변화한다는 것이다. Chang et al.(2016)에서 제시된 패널모형은 이러한 특성을 반영하여 전 세계 전력소비량 데이터로 소득과 시간에 따라 변하는 전력소비량을 추정하였다.
본 논문에서는 Chang et al.(2021, 2024)의 방법론을 이용하여 17개 광역 시도의 판매전력량이 소득수준과 시간에 따라 변화하는 공통요인(common factor)과 지역별 특수성을 반영하는 개별요인(idiosyncratic factor)을 식별하였다. 불균형 패널모형은 지역내총생산(GRDP: Gross Regional Domestic Product)을 변수로 사용하며, 여기서 추정된 소득계수는 전력소비량의 소득탄력성으로 이해할 수 있다.3) 따라서, 공통소득계수는 우리나라의 17개 광역 시도가 공유하는 전력소비량의 소득탄력성 패턴이며 개별소득계수는 17개 광역 시도의 특수성을 반영하는 소득탄력성 패턴이다.
판매전력량이 시간과 소득수준에 따라 변화하는 것은 두 가지로 생각할 수 있다. 첫 번째는 소득수준이 동일하지만 시점이 다른 경우이다. 서울특별시와 울산광역시를 예로 들면, 서울특별시의 2023년 1인당 GRDP는 약 4,642만 원이며, 울산광역시의 2000년 1인당 GRDP는 약 4,733만 원이다. 소득수준이 비슷하다 하더라도, 2000년과 2023년은 산업구조와 생활패턴 등이 매우 다르다. 예를 들면, 2000년대 초반에는 겨울철 난방용 전력수요가 여름철 냉방용 수요에 비해 매우 낮은 수준이었으나, 현재는 동계 최대전력이 매우 중요하게 평가된다. 따라서 소득수준이 비슷하다 하더라도 소득탄력성은 시간에 따라 다르다. 두 번째는, 동일 시점에서 지역별로 소득탄력성이 다를 수 있다는 점이다. 박정진・조영상(2022)에서는 에너지 다소비 업종의 에너지 소득탄력성이 에너지 저소비 업종의 탄력성보다 높다는 사실을 보였다. 따라서 중공업 중심의 에너지 다소비 업종이 집중된 울산광역시의 소득탄력성은 상대적으로 서비스업 비중이 높은 서울특별시의 소득탄력성보다 높을 수 있음을 예상할 수 있다.
본 연구에서 사용한 불균형 패널모형의 장점은 공통요인이 시간과 설명변수 자체에 의해 변화하면서도, 지역의 이질성을 통제할 수 있다는 것이다. 설명변수로는 지역내총생산을 사용하였는데, 이는 17개 광역 시도가 공유하는 소득탄력성이 시간과 지역 총생산에 따라 변화함을 의미한다. 17개 광역 시도별 판매전력량 예측에 사용한 함수계수 패널 분석(Functional Coefficient Panel Analysis)모형은 식 (1)과 같이 나타낼 수 있다. 해당 모형의 구체적인 추정 방식은 Chang et al.(2021)에 수록되어 있다.
: 1인당 판매전력량(자연로그)
: 1인당 GRDP(자연로그)
: 공통소득계수 (Income Coefficient of Electricity Sales)
, : 지역별 고정효과
,
식 (1)에서 는 지역으로 17개 광역 시도이며, 는 시간을 나타낸다. 와는 각각 지역 의 시작과 마지막 연도를 의미한다. 세종특별시를 제외하면 모두 2000년부터 2023년까지 자료가 있고 세종특별시는 2013년부터 2023년까지 자료가 있으므로 불균형 패널모형을 이용하면 17개 광역 시도 전체의 데이터를 이용할 수 있다는 장점이 존재한다.
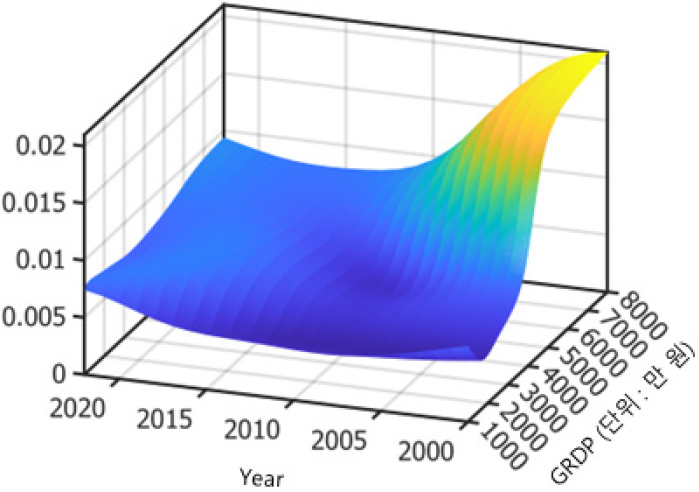
판매전력량 자료는 한국전력통계를, 인구는 통계청의 인구추계 자료를, GRDP는 산업연구원의 시장가격을 이용한 GRDP 실적과 전망을 이용하였다. 17개 광역 시도의 공통소득계수를 의미하는 는 비모수방법으로 추정하였으며, 시간과 GRDP에 의해 변화하는 함수계수이다. [그림 1]은 을 추정한 결과이다.
축은 시간이며, 축은 1인당 GRDP로 단위는 만 원이다. 시간이 지나면서 공통소득계수가 증가하지만, 증가하는 수준은 2010년대 중반 이후로 일정하거나 감소하는 모습을 보인다. 또한, 2010년대 중반 이전에는 소득이 증가하면서 소득계수가 증가하다가 4,000~5,000만 원 범위를 지나면서 감소하는 모습을 보인다. 이러한 이유 중 하나는 2010년대 중반에 1인당 소득수준이 5,000만 원보다 높은 지역이 울산광역시밖에 없기 때문에 추정치 자체가 불안정한 것으로 판단된다. 하지만 2010년대 중반 이후로는 소득에 따른 공통소득계수의 차이가 미미한 것으로 나타났으며 소득의 증감에 따라서는 소득계수에 큰 변화가 없는 것으로 추정되었다.
불균형 패널모형을 추정하고 난 후에는 공통소득계수와 개별소득계수의 유의성을 평가하고, 편의를 보정하기 위해 붓스트랩(bootstrap)방법을 활용한다. 또한, 모형에서 직접적으로 고려하지 않은 산업구조 변화에 따른 판매전력량 변화를 추정한다.
3. Bootstrapping을 통한 편의 보정
판매전력량과 지역 내 총생산은 비정상(nonstationary) 시계열로 일반적인 방법으로 추정하면 추정량에 편의(bias)가 발생할 수 있고, 판매전력량에 영향을 주는 가격변수 등을 통제하지 않고 추정하면 편의가 발생할 수 있다. 따라서, 본 연구에서는 지역별 잔차를 공통요인과 개별요인으로 분해하고, 이들의 시계열적 특성을 모형화할 수 있는 붓스트랩 방법을 활용하여 편의를 보정했다.4) 붓스트랩의 추가적인 장점 중 하나는 모형의 개별요인뿐만 아니라 시간과 소득의 함수로 표현된 공통요인의 표준오차를 계산할 수 있고, 이를 통해 계수들의 유의성을 평가할 수 있다는 점이다. 부록의 [부록 그림 1]와 [부록 그림 2]는 각각 소득계수 추정량의 편의와 표준오차를 나타내고, <부록 표 1>에는 지역별 편의 보정 전후의 개별소득계수와 표준오차가 수록되어 있다.
공통소득계수 추정량의 편의는 약 0.08~0.2의 범위에 있는데, 2000년대 초반에는 1인당 소득이 높은 구간에서 데이터가 존재하지 않기 때문에 1인당 소득이 증가할수록 편의가 증가하는 것으로 추정되었다. 개별소득계수는 지역별로 보정되는 편의에 차이가 있다. 예를 들면, 전라북도는 개별소득계수가 0.298에서 0.035로 약 88% 감소하였으나 경기도의 개별소득계수는 -0.159에서 -0.140으로 약 11% 감소했다. 개별소득계수의 표준오차를 통해 지역별 개별소득계수의 유의성을 평가하였는데, 세종특별자치시와 울산광역시의 개별소득계수는 유의하지 않은 것으로 나타났다. 이러한 결과는 세종특별시는 신규도시로 데이터의 개수가 다른 광역 시도에 비해 작으며, 울산광역시는 다른 도시에 비해 산업구조와 GRDP가 매우 다르기 때문으로 판단된다. 2023년 울산광역시의 1인당 GRDP는 7,076만 원인 반면, 전국의 1인당 GRDP는 3,864만 원으로 그 차이가 매우 크다.5) 개별소득계수가 양수인 지역 중 다수는 울산광역시, 전라남도, 충청남도 등과 같이 화학산업이나 철강산업 등 중공업 단지가 위치한 곳이다. 이러한 지역들은 개별소득계수 가 다른 지역에 비해 높게 추정되었다. 또한, 서울, 인천, 대구 등은 전국 대비 산업용 소비량의 수요가 낮아 계별소득계수가 음수로 추정됨을 확인할 수 있었다.
편의가 보정된 공통/개별소득계수를 활용하여 지역별 판매전력량을 추정하고 최근 5년(2018~2022년)의 추정오차를 계산한 결과,6) 1인당 판매전력량이 전국보다 높으면서 산업단지가 밀집한 경상북도, 울산광역시, 전라남도, 전라북도와 충청남도의 추정오차가 다른 지역에 비해 비교적 크게 나타났다([그림 2]). 이는 소득 이외에 산업구조의 변화가 판매전력량에 영향을 미칠 수 있음을 시사한다. 이외의 지역에서는 추정오차가 0.02 내외로 매우 정확한 모습을 보인다.
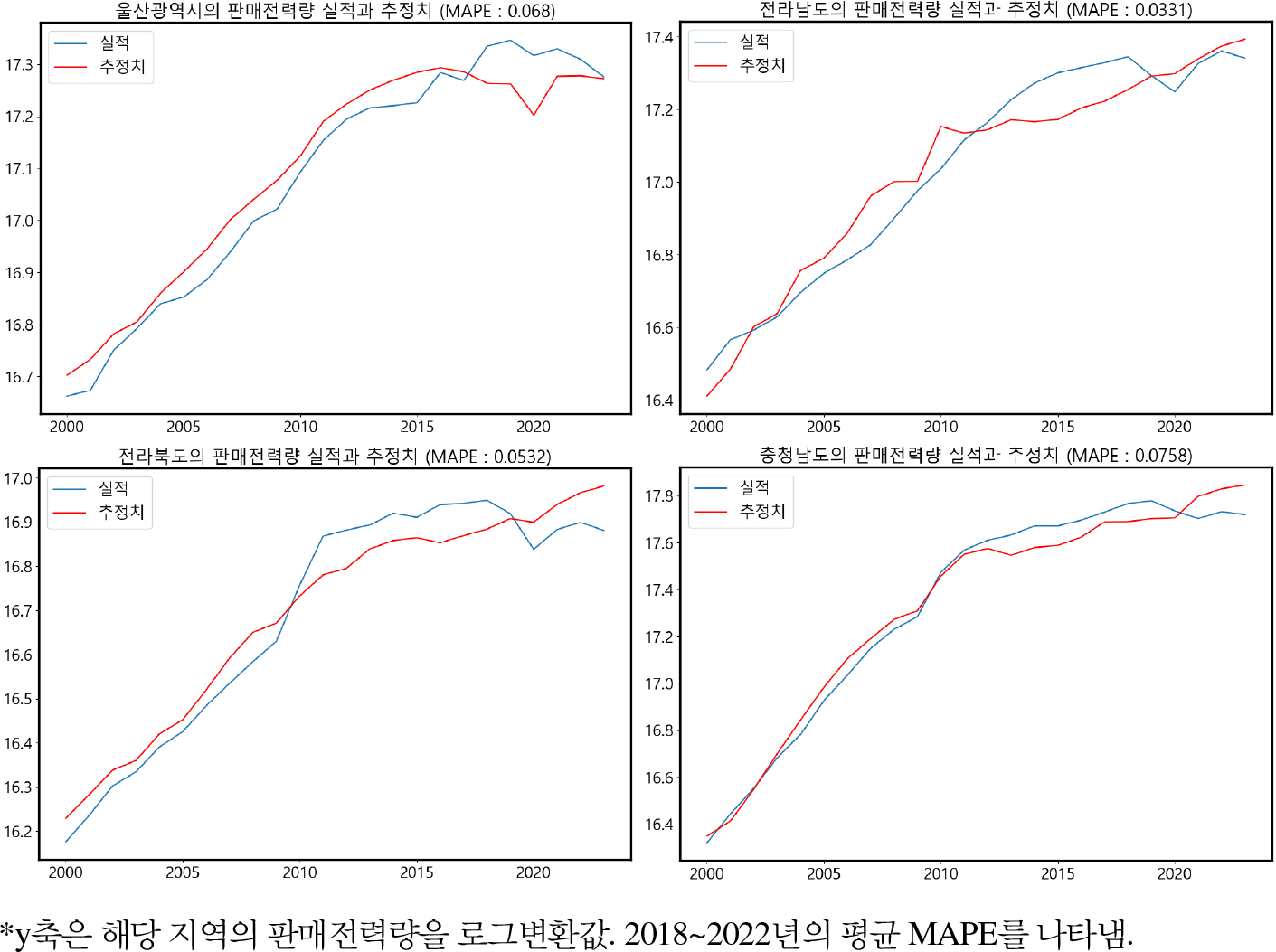
울산광역시는 GRDP가 감소했지만, 판매전력량이 증가한 구간에서 오차율이 크게 나타났다. 예를 들면, 2009년과 2018년에 GRDP가 감소했지만, 판매전력량은 증가했다. 전라남도와 전라북도에서 예측오차가 증가한 공통적인 이유는 GRDP 증가율보다 판매전력량 증가율이 더 크게 실현되었기 때문이다. 두 지역의 개별소득계수가 여타 지역에 비해 높게 추정되었음에도, 그 추정치 이상으로 판매전력량이 증가하였다. 예를 들면, 전라남도는 2010년 대비 2022년의 GRDP가 약 14% 증가한 반면 판매전력량은 약 28%가 증가하였다. 또한, 전라북도는 2009년 대비 2011년의 GRDP가 약 9% 증가한 반면 판매전력량은 약 27%가 증가하였다. 다음 장에서는 이와 같은 산업구조의 변화가 판매전력량에 미치는 서로 다른 영향을 추정하고 이를 판매량 모형에 반영하고자 한다.
4. 지역별 산업구조 변화
본 논문에서는 C-Lasso(Classifier-Least Absolute Shrinkage and Selection Operator) 방법으로 불균형 패널모형에 산업구조의 변화를 반영하였다. C-Lasso 방법론은 Su et al.(2016)에서 처음 제시된 Lasso 기법의 하나로, 패널데이터 추정에서 데이터의 이질성(heterogeneity)을 적절히 고려하지 않으면 추정량이 비일치(inconsistency) 추정량이 될 수 있는 문제를, 유사한 특성을 가진 그룹으로 자동으로 묶어서 추정함으로써 문제를 해결할 수 있는 방법론이다. 윤용기・최용옥(2022)은 이를 이용하여 도시가스 수요의 특수일 변동성 문제를 추정하였다. 본 논문에서는 아래와 같이 전력수요 산업지수를 구성하고 산업구조변화에 따른 판매전력량 변화를 C-Lasso를 통해 반영함으로써, 일부 지역별 소득계수의 불안정성을 해결하고 지역별 이질성을 모형화하고자 하였다. 먼저 (2)와 같이 원단위를 계산한 다음 기준연도를 100으로 지수화한다. 이후 (3)에서처럼 전력수요 산업지수를 구성한다.
전력수요 산업지수는 지역별 산업구조에 따른 전력 수요량을 나타내는 지수로 해석할 수 있다. 지역별 전력수요 산업지수를 구성하기 위해서는 부문별 전력소비량과 부가가치 자료가 필요하다. 지역별・부문별 전력 사용량 구성에는 한전의 AMR자료 중 본부별・세부 업종별로 구분된 것을 사용하였고, 지역별・부문별 부가가치 구성에는 산업연구원의 부문별 부가가치 자료를 사용하였다. 본 연구에서 전력수요 산업지수를 2011년부터 2022년까지 구성하였는데, 이는 연구에 사용할 수 있는 AMR자료가 해당 기간만 존재하기 때문이다. AMR 자료는 15개 본부별 데이터이며 부가가치는 17개 시도별 자료이기 때문에 두 데이터 간의 통합된 지역이 필요하다. 예를 들면, AMR자료는 경기북부와 경기를 구분하고 있는데, GRDP자료는 이를 경기도로 통합하여 구분한다. 본 연구에서는 17개 지역 중 부산과 울산을 통합하고 대전, 세종과 울산을 통합하여 17개 지역을 13개 지역으로 구분하였다. 또한, AMR과 GRDP의 세부 업종은 각각 73개와 23개로 서로 다른 세분류가 존재하여 이를 8개 대업종으로 통합하여 구분하였다. 이처럼 재분류된 업종별 데이터를 이용하여 산업구조의 영향을 추가로 모형화하였다. 추정 과정은 아래 식 (4)로 표현할 수 있다.
여기서 는 13개 지역이며 Index는 지역별 전력수요 산업지수이고, 은 지역별 추정오차를 의미한다. 불균형 패널모형에서 자연로그를 취하여 추정했기 때문에 도 자연로그 단위이며, 결과를 탄력성으로 해석하기 위해 전력수요 산업지수에도 자연로그를 취했다. 모형을 추정하기 위해서는 아래의 를 최소화하는 𝛿와 𝜏를 찾아야 한다(식 (5)).
식 (3)에서 , 이며,으로 주어진다. C-Lasso의 하이퍼파라미터(hyperparameters)는 그룹의 개수인 와 𝜆인데, 아래 식 (6)을 최소화하는 와 𝜆조합으로 결정할 수 있다.
본 논문에서 추정된 최적의 그룹 개수 가 3이며, 𝜆는 1.3일 때 값이 최소화되었다. 그룹 개수를 3개로 설정하여 C-Lasso모형을 추정한 결과, 각 그룹의 는 0.174, 0.430과 1.267로 추정되었다. 첫 번째 그룹은 전력수요 산업지수가 한 단위 증가할 때 전력수요가 0.174%만큼 증가하는 것을 의미한다. 두 번째와 세 번째 그룹은 산업구조가 전력수요에 미치는 영향이 큰 그룹인데, 두 번째 그룹에는 경기도, 부산・울산과 제주도가 포함되며 세 번째 그룹에는 대전・충남・세종과 전라북도가 포함된다. 이들 지역 중 울산광역시, 충청남도와 전라북도는 산업용 수요가 상대적으로 매우 커서 앞 절에서 확인했듯이 추정오차가 상대적으로 큰 지역들이다.
<표 2>는 2018~2022년 기간 동안 산업구조 변화에 의한 판매전력량 변화를 반영하기 전과 후의 추정오차를 나타낸다. 일부 지역에서는 추정오차가 오히려 증가하였지만, 추정오차가 컸던 지역 대다수에서 산업구조 변화 효과를 반영한 후에는 오차가 감소하여 전국적으로는 추정오차가 줄어드는 것을 확인할 수 있었다.
<표 2>
산업구조 변화 효과 적용 전후의 MAPE
전력수요 산업지수를 만드는 과정에서 AMR과 GRDP의 자료구분을 통합해야하는 제약 때문에 17개 지역이 아니라 13개 지역에 대해서만 산업구조의 변화를 평가할 수 있었지만, 본 모형을 통해서 산업구조의 변화를 반영하는 것이 전체적인 모형적합도를 향상시키는 것을 확인할 수 있었다.
5. 소득계수 평면 확장 및 지역별 판매량 예측
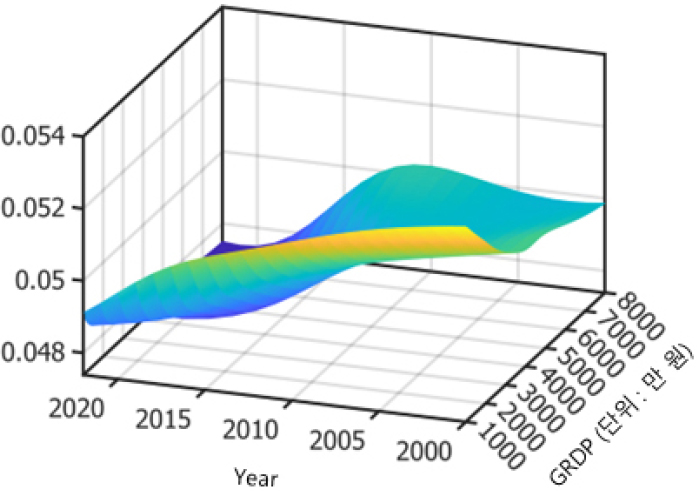
본 연구에서 사용한 공통소득계수는 시간과 GDP에 대한 함수로, 지역별 판매량 예측을 위해서는 함수계수를 시간 축으로 확장해야 한다. 현재 T시점에서 h기간 만큼 예측하기 위해서는 의 계수 값을 알아야 한다는 의미이다. 하지만, 전력 패널모형에서 1인당 소득은 8,000만 원까지 추정하였고 울산을 제외한 16개 광역 시도의 2038년 1인당 소득 예측치는 8,000만 원 이하이기 때문에, 향후 15년 예측을 위해서는 시간 축으로만 공통소득계수를 확장하면 된다. 울산은 8,000만 원에서의 계수가 10,000만원 이상까지 고정된다고 가정하였다. 시간 축으로 함수의 평면을 확장하기 위해서 공통소득계수 를 함수 시계열로 보고 이를 Chang et al.(2021)과 Chang et al.(2024)에서 제시된 FPCA 방법을 활용하여 확장한다. FPCA를 이용하여 함수 평면을 확장하는 방식에 대한 자세한 설명은 본 논문에서는 생략하기로 한다. 이를 활용하여 확장한 소득계수 평면은 [그림 3]와 같다. x축은 시간이며 y축은 소득으로, 단위가 만 원이다.
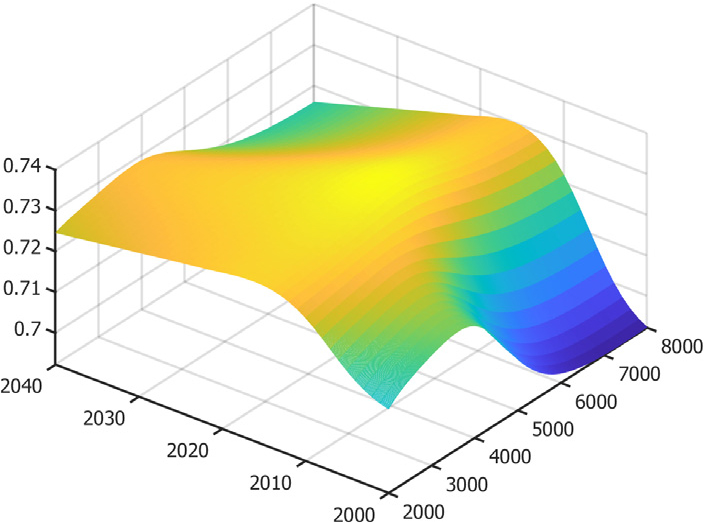
공통소득계수는 2020년 이후 시간이 지나면서 감소하며, 소득이 높은 지역에서 그 특성이 두드러진다. 이는 소득이 증가할수록 에너지 수요의 소득탄력성이 감소하는 것으로 해석할 수 있다. 2000년도 부근에서 소득이 증가하면서 소득계수가 감소하는 것처럼 보이는 것은 2000년 초에는 지역별 소득이 5천만 원 이상인 곳이 존재하지 않기 때문으로, 해당 구간은 통계적으로 유의미하지 않다고 판단된다.
<표 3>은 2017년까지 자료를 활용하여 2019년부터 2023년까지의 1-5년 까지의 예측력을 평가한 예측실험 결과이다. 세종특별자치시는 데이터 기간이 매우 짧으며 이용할 수 있는 대부분의 기간 중 급격한 인구변동 등의 효과가 포함되어 있어 예측실험에서 제외하였다. 2019년 행은 2018년에 예측한 1년 뒤(one year ahead forecasting)의 예측에 대한 평가이고, 2023년 행은 2018년에 예측한 5년 뒤(five year ahead forecasting)의 예측에 대한 평가이다. 데이터의 시계열이 20년 정도밖에 되지 않아 더 장기의 예측실험을 하기 어려웠지만, 결과를 보면 개별소득계수가 높은 충청남도, 전라북도, 전라남도는 대체로 과소예측을 한 것으로 나타났다. 이들 지역은 팬데믹 기간인 2020년에 예측오차가 증가하였는데, 팬데믹 기간 동안 산업단지가 밀집한 지역이 더 크게 영향을 받았기 때문인 것으로 추정된다. 전체적으로 산업단지가 많은 울산, 전남・북, 충남 등을 제외하고는 서울특별시나 경기도 등에서는 약 5% 내외의 예측오차를 보이며, 제주를 제외한 나머지 광역 시도에서는 3% 내외의 예측오차를 보여 중장기 예측력이 매우 안정적인 것으로 판단된다.
<표 3>
불균형 패널모형 예측력 평가
6. 머신러닝 기법을 이용한 지역별 판매전력량 예측
본 절에서는 위에서 설명한 불균형 패널모형의 예측 강건성을 확인하기 위해 머신러닝 기법의 일종인 Gradient Boosting 방식을 이용하여 17개 광역 시도의 1인당 판매전력량 증가율을 개별적으로 예측하여 불균형 패널모형과의 예측력 성과 차이를 분석하고자 한다. 불균형 패널모형을 이용한 앞 절의 모형은 17개 광역 시도 전체를 데이터로 개별적 이질성을 여러 가지 방법으로 통제한 상태에서 시간에 따라 변동하는 공통소득계수와 개별소득계수 추정을 통해 지역별 판매량을 중장기적으로 예측하는 방법이다. 머신러닝을 이용한 개별모형은 세부 지역 정보를 추가로 이용하여 개별 시도의 판매전력량 증가율을 예측하는 방법이다. 본 연구의 최종 목표가 지역별 수요의 합인 전국 수요를 예측하는 것은 아니지만, 불균형 패널모형을 Top-Down 방식에 가까운 모형이라고 볼 수 있을 것이고 개별모형으로 지역별 수요를 추정하는 것은 Bottom-Up에 가까운 방식이라고 볼 수 있을 것이다. 본 절에서는 앙상블 학습 방법의 일종으로 여러 개의 결정 트리(decision trees)를 효율적으로 조합하여 작동하는 XGB(eXtreme Gradient Boosting)를 적용하여 지역별 판매량을 연별로 예측하고자 한다. XGB는 Gradient Boosting 일종이지만 방법과 다른 방법들과 차별화되는 몇 가지 특성이 있다. 기존의 Gradient Boosting 방법들에 비해 정규화를 사용하여 통해 과적합(overfitting)을 방지할 수 있으며, 각 트리를 구성할 때 불필요한 가지를 제거하여 트리의 깊이를 제한하여 추가적으로 과적합을 방지한다. 또한, 특성 중요도(Feature Importance)를 통해 설명변수(features)들이 예측에 얼마나 기여하는지를 계산하여 변수의 예측 중요도 해석이 가능하다.
본 절에서는 기존 XGB의 방법을 이용하되, 시계열 자료의 추세 및 종속성을 고려하였다. 불균형 패널모형에서는 종속변수를 지역별 1인당 판매전력량으로 설정한 반면 개별모형은 비정상 시계열의 가능성을 배제하기 위해 종속변수를 지역별 1인당 판매전력량 증가율로 설정하였다. 설명변수로는 1인당 GRDP, 1인당 전력소비량 증가율, 추세, 그 외의 세부적인 22개의 업종별 부가가치로 총 25개를 사용하였다. 종속변수가 1인당 판매전력량 증가율이므로, 추세를 제외한 모든 설명변수는 증가율로 변환하여 사용하였다. 또한, 개별모형에서는 관측치 숫자가 부족한 세종시의 예측치는 제외하였다.
XGB를 활용한 개별모형을 추정하여 지역별 특성 중요도를 분석해 보면7) 대체로 GRDP와 1인당 총소비량 증가율이 중요한 변수로 선택되었다. 또한, 지역별 특성에 맞는 부가가치 증가율이 함께 중요한 변수로 선택되었다. XGB를 이용하여 2019년과 2021년을 기준으로 한 향후 2년 예측력 평가 결과는 <표 4>에 나타나 있다. XGB모형의 특성상 앞 절의 불균형 패널모형과는 다르게 3-5년 중장기 예측성과는 불안정적으로 나타나 중장기 예측에는 적합하지 않음을 확인할 수 있었고 이에 따라 불균형 패널모형과와 비교는 1-2년 예측 성과를 기준으로 하였다. 예측실험 결과 XGB모형의 1-2년 예측오차는 불균형 패널모형의 <표 3>의 1-5년 예측 결과와 비슷한 정도로 나타났다. XGB모형을 이용한 지역별 예측은 중장기 예측에 사용하기는 어려운 측면이 존재하나, 1-2년 지역별 판매량 예측에는 보완적으로 사용할 수 있을 것으로 판단된다. 이를 통해 불균형 패널모형의 중장기 지역별 판매량 예측 성과가 전체적으로 강건함을 확인할 수 있었다.
<표 4>
개별모형 예측력 평가
Ⅲ. 지역별 비동시 최대전력 모형
지역별・월별 최대전력을 분석하고 예측하기 위해서는 지역별・시간별 부하 자료를 통해 월별 최대전력과 월별 최대전력이 실현되는 시간을 분석해야 한다. 하지만 지역별・시간별 부하는 기존에 문헌이나 연구에서 사용되지 않았을 뿐만 아니라, 현재 가용한 데이터가 매우 불안정적이다. 본 연구에서는 지역별 최대전력 모형 구축에 앞서 지역 부하를 정확하게 정의하고 그에 따른 지역 부하 자료를 재구축한다.
1. 지역 부하 데이터 현황
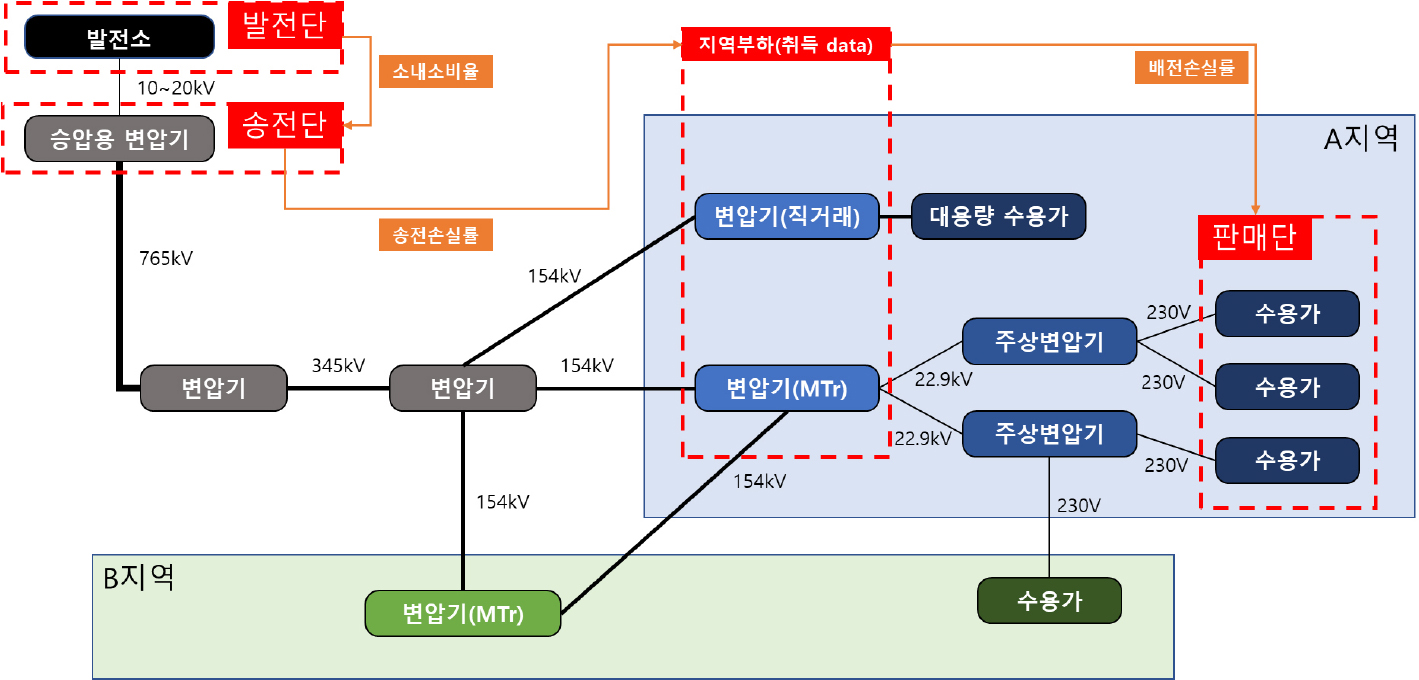
지역 부하는 지역 내 총부하를 의미하는 것으로, 지역별 주변압기(MTr, Main Transformer)와 직거래 데이터로 추정된 자료이다.8) 부록의 [부록 그림 3]는 지역 부하의 개념도를 나타내는데 총발전량에서 소내소비량과 송전손실량을 제외한 것이 지역 부하로 정의되며, 이는 주변압기 데이터에 직거래 데이터를 더한 것과 동일하다.
시간별 지역 부하 자료는 17개 광역 시도별로 구분되어 있으나, 본 연구에서는 17개 광역 시도를 <표 5>와 같이 9개 지역으로 나누었다. 그 이유는 실시간 계량이 되지 않는 1MW 이하의 한전 전력구매계약 물량(PPA: Power Purchase Agreement)과 소규모 자가용 태양광(BTM: Behind the Meter)의 데이터 구분이 9개 지역으로 되어있기 때문이다. 따라서 시간별 지역 부하 자료는 17개 광역 시도로 구축할 수 있으나 계통에 따른 지역별 비동시 최대전력 분석과 예측은 현재 9개로 구분된 지역으로만 가능하다. 본 연구에서는 17개 광역 시도를 9개의 지역으로 재분류하고 예측 대상을 9개 지역으로 설정하였다.
본 논문에서의 지역 부하 자료의 기간은 2013년 1월 1일부터 2022년 12월 31일까지 87,648개의 관측치가 존재하는데, 이를 이용하여 지역별 비동시 최대전력 자료를 구축하는데 크게 두 가지 문제가 있다. 첫 번째는 원자료에 이상치(outliers)와 결측치(missing values)가 다수 존재하여 정확한 지역 부하 분석을 위해서는 결측치와 이상치를 탐지하여 보간하는 작업이 필요하다는 점이다.
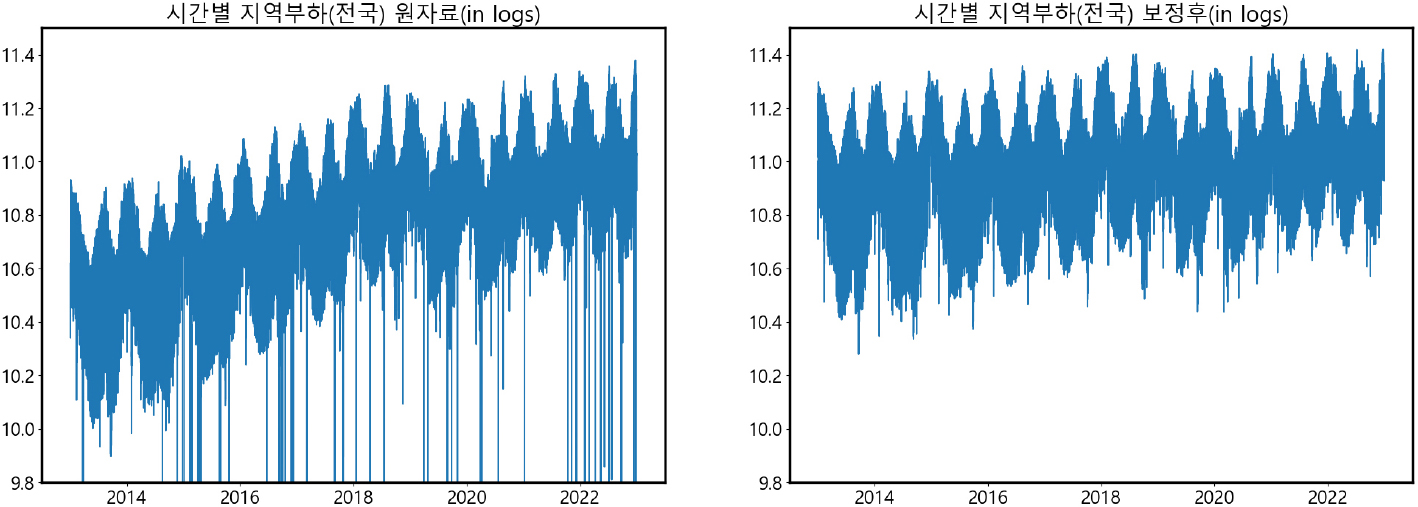
두 번째는 지역 부하와 유사한 판매단 자료를 구축하여 지역 부하와 비교한 결과 지역 부하 자료는 연별로 과소하게 취합된 것으로 확인되었다. [그림 C]에서 볼 수 있듯이 지역 부하 자료에서 배전손실량을 뺀 값은 사소한 차이를 제외하고 판매단 데이터와 일치해야 한다. 즉, 한국전력통계의 판매전력량에 배전손실량을 더한 값과 지역 부하 값은 일치하여야 한다.본 연구에서는 두 자료의 연별 합을 비교하였는데, <표 6>에서 나타나듯 지역 부하의 연별 합은 판매전력량에 배전 손실량을 더한 값보다 낮게 나타났다.9) 이러한 이유가 발생하는 첫 번째 이유는 지역구분의 차이로 인해 지역 부하와 지역별 판매단 데이터에 배전손실량을 더한 값이 일치하지 않을 수 있다는 것이며, 두 번째 이유는 검침구의 차이로 인해 지역별 판매단 데이터와 한국전력통계의 판매전력량 데이터가 다를 수 있다는 점이다. 하지만, 두 가지 데이터의 차이는 크지 않아야 하며 만약 그 차이가 유의미하게 다르다면 구축된 시간별 지역 부하 데이터에 문제가 있다고 판단할 수 있을 것이다.
<표 6>을 통해 전체 기간에 걸쳐 지역 부하의 연별 합이 판매전력량에 배전손실량을 고려한 값보다 작게 추정된 것을 확인할 수 있었다. 물론 2013년에 비해 시간이 지날수록 두 데이터의 차이가 줄어들어 2022년에는 지역 부하가 판매전력량의 약 93%까지를 커버한다. 지역별 월별 합계에서도 이와 같은 현상이 동일하게 나타남을 확인할 수 있었고, 이렇게 지역별 시간별 부하의 합이 전국의 합과 차이가 나는 것은 지역별 시간별 부하 원시 데이터 구축에 문제가 있기 때문으로 판단된다.
본 논문에서는 지역 부하 자료 보정을 두 단계로 나누어 시행한다. 먼저 지역 부하의 이상치와 결측치를 탐지하여 보정하고, 그다음 월별 판매전력량의 추세를 활용하여 지역 부하의 추세를 보정한다.
<표 6>
(판매전력량 + 배전 손실량 대비) 지역 부하(연별 합)
| 연도 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
| 비율(%) | 67.81 | 69.00 | 72.78 | 79.04 | 84.11 | 89.42 | 88.20 | 91.01 | 93.00 | 93.02 |
2. 지역 부하 이상치/결측치 선형 보간 및 추세 보정
1절에서 설명한 데이터의 문제를 해결하기 위해 먼저 이상치와 결측치를 탐지하고 해당 구간을 선형 보간하는 방법을 사용한다. 먼저 전체적인 추세를 판단하기 위해 비모수 방법 중 국소선형회귀(local linear) 방법으로 자연로그를 취한 지역 부하 자료의 추세를 추출하였다.10) 다음으로, 추출한 추세에서 70% 이상 감소하는 자료를 이상치로 판단하여 제거하였다. 여기서 하한선은 특수일 효과에 따라 감소하는 자료가 제외되는 것을 방지하기 위해 70%로 설정하였다.11) 마지막으로, 제거된 관측치를 선형 보간하여 이상치와 결측치를 보정하였다.
시간별 부하 데이터와 월별 판매량의 불일치는 시간이 갈수록 감소하지만, 전체적으로 거의 모든 기간 연별/월별 데이터가 일치하지 않아 이상치와 결측치를 보정하는 것 이외의 방법이 필요하다. 이를 위해 우리는 판매전력량의 추세가 전체적인 전력 수요량의 추세와 유사하다는 가정하에 지역별 시간별 부하의 추세도 판매량의 추세와 유사하다는 가정을 도입한다. 시간별 부하 데이터가 모든 연월에 걸쳐 과소 산정되었고 이를 실제 지역별로 판매된 데이터의 추세로 보정하는 것은 매우 자연스러운 가정이라고 판단된다. 다만 지역 부하는 시간별 자료인 반면 판매전력량은 월별 자료이기 때문에 두 자료의 빈도(frequency)를 일치시키는 과정이 필요하고, 이에 따라 이상치와 결측치가 보간된 지역 부하 자료를 월별로 합하여 두 자료를 비교하였다.
월별로 빈도를 맞춘 지역 부하의 월별 합과 판매전력량 자료의 추세를 국소선형회귀 방법을 사용하여 각각 추출한다. 여기서 구한 추세는 월별 자료에서 추출한 것이기 때문에 이를 시간별 추세로 변환하여 다시 시간별 데이터를 재구축하는 과정이 필요하다. 따라서 추출한 월별 추세를 시간별로 선형 보간하여 시간별 추세를 복원하고, 이를 바탕으로 지역 부하의 원자료를 월별 판매전력량의 추세에 맞도록 보정하였다. [그림 4]는 9개 지역의 지역 부하를 최종적으로 보정하고, 이를 전국 단위로 합한 그림이다.
<표 7>은 위와 같은 보정 결과를 검증하기 위해 지역 부하의 연별 합과 판매전력량에 배전 손실량을 더한 값을 비교한 결과를 보여준다. 모든 연도에 걸쳐 그 차이가 유의미하게 다르지 않았으며, 대부분의 월별 데이터도 보정된 자료와 판매량의 차이가 미미한 것으로 나타나 본 논문에서의 보정 방식이 연별 및 월별로 안정적임을 확인할 수 있었다.
<표 7>
(판매전력량+ 배전 손실량) 대비 구축된 자료(지역 부하의 합)
| 연도 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
| 비율(%) | 100 | 100 | 100 | 100 | 100 | 101 | 99.6 | 100 | 100 | 99.7 |
3. 비동시 최대전력 예측모형
3절에서는 보정된 지역별 시간 부하 자료를 바탕으로 지역별・월별 최대전력을 추정하고 예측하는 모형을 제시하고, 4절에서는 예측력을 평가한다. 최대전력 시계열은 기본적으로 판매량과 매우 강한 상관관계를 가지고 있어, 지역별 최대전력 예측에는 2장에서 예측한 지역별 판매전력량 예측치를 이용할 수 있는 모형을 제시한다. 보정된 지역 시간 부하 자료를 이용하여 9개 지역의 월별 최대전력 전력 자료를 구축한 후, 아래와 같이 추세와 계절성을 분리해서 추정하는 모형으로 지역별・월별 최대전력 모형을 구성하였다.
식 (7)에서 는 월별 최대전력, 은 월별 최대전력의 추세, 는 월별 최대전력의 기온효과, 그리고 은 지역을 의미한다. 최대전력 예측모형에서 월별 최대전력의 추세는 국소선형회귀 방법으로 추정하고자 한다.
최대전력의 계절성은 주로 기온에 의존하는데 본 논문에서는 기온효과로 모형화한다. 이 개념은 기존의 연구에서 김인무 외(2011), 김점수 외(2011), 이성로(2017), 최용옥・박혜성(2020), 신학림 외(2024) 등에서 사용된 기온효과 변수와 유사하다. 즉, 기온효과는 주어진 기온과 당시의 기온이 최대전력에 얼마나 민감하게 영향을 미치는지를 나타내는 기온반응함수(Temperature Response Function)를 먼저 추정하여 지역별로 최대전력이 기온에 반응하는 정도를 추정하는 방식이다. 기존의 연구에서는 대부분 FFF(Fourier Flexible Form)를 이용하여 기온반응함수를 비모수적으로 추정하였는데 본 연구에서는 최대전력수요가 기온과 시간에 따라서 비선형적으로 변화하는 것을 효과적으로 모형화하기 위해 비모수 추정 방법의 하나인 LOWESS(Locally Weighted Scatterplot Smoothing)를 사용하였다.12)
본 연구에서는 누적 기온의 최대전력 반응도를 정확하게 모형화하기 위해 72시간 시간별 평균기온을 사용하여 기온반응함수를 추정하였다. 시간별 기온 데이터는 매우 세분화된 지역으로 주어져 있어, 인구 가중평균을 이용하여 9개 지역의 기온을 산출하였다. 모형에서 사용한 기온은 9개 지역 각각에서 최대전력이 실현된 시점에서의 72시간 평균기온을 사용한다. 최대전력 모형을 통해 9개 지역의 최대전력을 추정하고 MAPE로 나타낸 추정오차를 계산한 결과는 <표 8>과 같다. 전국을 기준으로 MAPE가 약 0.02이며, 강원을 제외한 대다수의 지역에서 MAPE가 0.02~0.04 내외임을 확인하였다.
<표 8>
지역별 비동시 최대전력 추정오차(2013~2022, MAPE)
| 지역 |
서울・경기・ 인천 | 강원 |
부산・울산・ 경남 | 대구・경북 | 광주・전남 |
| MAPE | 0.026 | 0.053 | 0.023 | 0.026 | 0.03 |
| 지역 | 전북 | 대전・충남・ 세종 | 충북 | 제주 | 전국 |
| MAPE | 0.027 | 0.037 | 0.025 | 0.027 | 0.02 |
중장기 지역별 최대전력을 예측하기 위해서는 식 (3)에서 나타난 것처럼 추세의 예측치와 기온효과 부분의 기온 전제가 필요하다. 기온 전제로는 최근 5년의 최대전력이 걸린 시점의 월별기온을 평균하여 사용하였다. 예를 들면, 7월의 기온은 2018년부터 2022년까지 지역별 최대전력이 걸린 시점의 72시간 평균기온을 이용했다.
최대전력의 추세 부분은 Alsaedi and Tularam(2020) 등 기존의 많은 문헌에서 보이듯이 최대전력과 판매전력량의 관계는 거의 일대일의 상관관계를 지니고 있고 그 추세는 매우 비슷하게 나타난다. 따라서, 본 논문에서는 2장의 불균형 패널모형에서 산출한 지역별 판매전력량 예측치를 사용하여 최대전력의 추세를 추출하고자 한다. 2장의 판매전력량 예측치는 연별 값에 해당하므로 본 연구에서는 월별로 선형 보간하여 사용한다. 이를 활용하여 아래의 식 (8)과 같이 지역별 최대전력 추세와의 관계를 추정하였다.
: 연별・지역별 총판매량을 월별로 선형 보간한 값
: 월별・지역별 최대전력의 추세
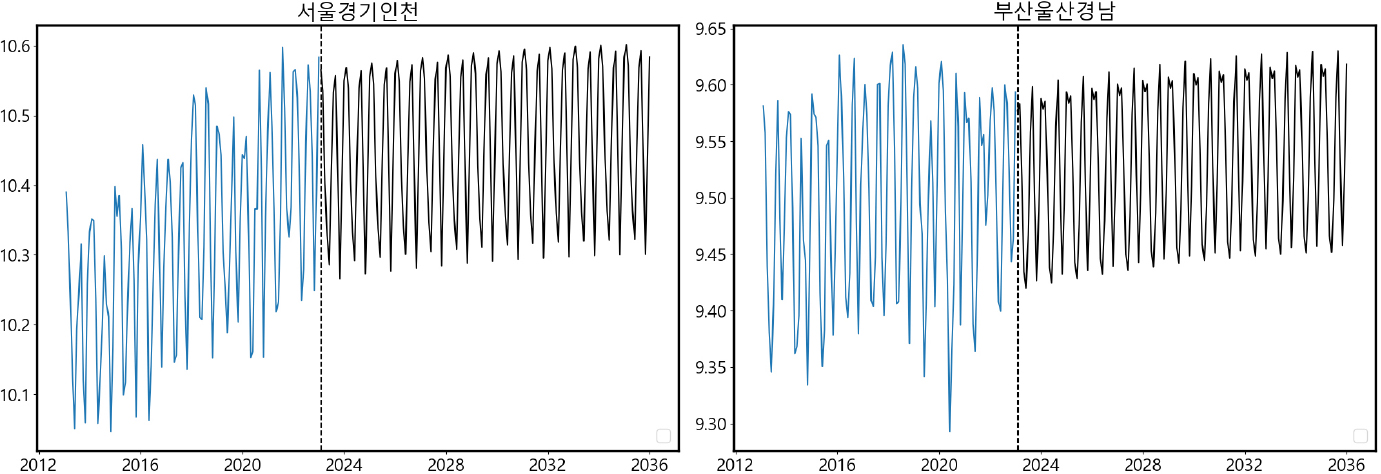
여기서 은 연별・지역별 총판매량을 월별로 선형 보간한 값이고, 은 월별・지역별 최대전력의 추세를 나타낸다. 는 시간에 따라 변동하는 시간변동계수로 판매량과 최대전력의 장기관계가 시간에 따라 변하도록 하였다. 최대전력과 판매량의 추세는 거의 비슷하지만 지난 10년 동안의 데이터를 분석해 보면 지역별 판매전력량이 증가하는 속도보다 지역별 최대전력이 증가하는 속도가 빠른 경우가 대부분이었고, 이에 따라 를 시간 변동하게 모형화하는 것이 적합하다고 판단하였다. 추세와 기온효과 예측치를 반영하여 9개 지역 중 대표 지역13)의 월별 최대전력 예측치를 산출한 결과는 [그림 5]에 나타나 있다.
4. 비동시 최대전력 예측결과
<표 9>는 1년씩 예측한(rolling forecast) 실험 결과이다. 예측실험 결과 모든 지역에서 5년 평균 약 3-4.5% 정도의 예측오차를 확인할 수 있었다. 2020년의 경우 팬데믹 효과로 예측오차가 증가하는 경향이 있으나, 이듬해인 2021년과 2022년의 예측오차는 다시 감소하는 모습을 보인다. Xia et al.(2023) 등에 의하면, 최대전력은 판매량에 비해 계절성이 강하고 기온에 따른 변동이 크기 때문에 예측오차가 판매량 예측오차보다 매우 크게 나타나는 것으로 알려져 있다. 또한, 지역 부하 자료의 정확도가 낮은 점을 고려할 때 본 논문에서의 지역별 최대전력 예측력은 매우 안정적이라고 판단된다.
<표 9>
지역별 1년 최대전력 예측평가
Ⅳ. 결 론
본 논문에서는 기존의 문헌에서 거의 연구되지 않았던 중장기 지역별 판매전력량 및 최대전력을 추정하고 예측하는 방법을 제시하였다. 먼저 안정적인 데이터가 존재하는 지역별 판매전력량 데이터를 이용하여 중장기 판매량 모형을 구성하고 이를 이용하여 지역별 판매전력량을 예측하였다. 또한 상대적으로 매우 불안정적인 시간별 지역 부하 원시자료의 이상치와 결측치를 보간하고 추세를 보정하였다. 이렇게 보정된 시간별 지역 부하를 이용하여 지역별 최대전력을 예측하는 모형을 제시하였다.
17개 광역 시도별 중장기 판매전력량 예측을 위해서는 불균형 패널모형을 구성하여 지역의 공통적인 특성과 개별적인 특성을 추정하였다. 또한 지역별 특성에 따른 산업구조 효과를 추정하기 위해 지역별 전력수요 산업지수를 구성하고, C-LASSO방법을 활용하여 지역별로 산업구조가 판매전력량에 미치는 효과가 다른 것을 추정하였다. 추정 결과 화학산업이나 철강산업 등 중공업 단지가 위치한 울산광역시, 전라남도, 충청남도와 전라북도는 1인당 GRDP 성장률 대비 판매전력량 증가가 전국 평균보다 더 큰 것으로 나타난 반면, 부가가치당 전력 사용량이 적은 산업이 발달한 서울특별시는 1인당 GRDP 성장률 대비 판매전력량 증가가 전국 평균보다 작았다. 추정된 불균형 패널모형을 바탕으로 1-5년 예측실험 결과 MAPE로 평가된 불균형 패널모형의 예측오차는 대부분 지역에서 평균 3-5%로 나타났고, 신규도시인 세종특별자치시와 중공업 단지가 위치한 울산광역시, 전라남도, 전라북도와 충청남도는 전국 평균보다 그 예측오차가 상대적으로 크게 나타났다. 추가적으로 머신러닝 기법의 하나인 XGB 방법을 이용하여 지역별 판매량을 개별로 예측해 본 결과 1-2년 평균 예측오차는 불균형 패널모형에 준하는 것으로 나타나 우리 모형의 예측 강건성을 확인할 수 있었다.
본 논문에서는 지역별 시간별 부하의 원시자료가 판매전력량 데이터에 비해 과소하다는 사실을 확인하였고, 또한 다수의 이상치와 결측치가 있음을 확인하였다. 데이터 재구축을 위해 지역별 판매전력량 자료를 활용하여 보간 및 보정하였다. 이렇게 보정된 시간별 부하 데이터를 이용하여, 추세 및 기온 반응도가 시간에 따라 변화하는 최대전력 모형을 추정하고 중장기 예측을 시행하였다. 판매전력량의 추세 추정과 예측에는 불균형 패널모형에서 산출한 예측치를 사용하였다. 판매전력량 예측과 마찬가지로 1-5년 예측실험 결과, 지역별 중장기 최대전력의 예측오차는 모든 지역에서 5% 이내로 안정적으로 나타남을 확인할 수 있었다. 이러한 결과는 우리나라의 분산화된 전력시스템(Decentralized Power System)운영의 기초연구가 될 수 있을 것으로 판단된다.
본 논문에서 확인한 것처럼 안정적이고 정확한 지역 부하 자료를 수집하고 이를 체계적으로 보정하고 구축하는 추가적인 방법론이 필요해 보인다. 과거 자료에서 보이는 이상값 및 결측치 등은 본 논문에서 제시한 방법 이외에 다양한 머신러닝 등의 기법을 이용하여 지속적으로 보완해 나갈 필요가 있다고 판단된다. 또한 미래에 급증하리라 예상되는 전기화 전환수요, 데이터센터, 반도체 클러스터 등으로 인한 지역별 수요 증대 효과에 관해서도 추후 연구가 필요한 것으로 보인다. 마지막으로, 급증하고 있는 지역별 재생에너지 데이터를 효과적으로 구축하고 이를 바탕으로 하는 지역별 태양광 발전에 따른 수요 변동 분석에 관한 연구도 추후 연구과제로 남겨둔다.